Intro
Golf is a game of fine margins, and similar to many modern-day sports, data is becoming a larger part of players’ practice and on-course decision making.
The PGA Tour website is a great repository for player’s statistical performance throughout the tour’s calendar. Below you can see a basic introductory analysis I have performed; including some exploratory data analysis, as well as a regression to unlock some insights into what drives a good scoring average on the PGA Tour.
 All of my code can be found in the final section, or you can check out the full project on my GitHub.
All of my code can be found in the final section, or you can check out the full project on my GitHub.
Data Introduction
Before I commence with some exploratory data anaylsis, let’s clearly define all of our variables of interest:
| Variable | Description |
|---|---|
| player | Player’s name |
| rank | Player’s PGA Tour rank in the variable of interest |
| birdies_per_round | The average number of birdies a player makes in each PGA tour round (18 holes) |
| driving_avg | The average distance when driving off the tee (yds) |
| gir_pct | The percentage of greens each player reaches in regulation (GIR = Par -2 strokes) |
| scoring_avg | Each player’s average 18-hole score (strokes) |
| scrambling_pct | Percentage of holes that a player makes par-or-better, when failing to reach GIR (scrambling) |
| overall | Total performance in all of the above measured metics |
You can also find the .db file I used in the GitHub repo for this project.
Exploratory Data Analysis
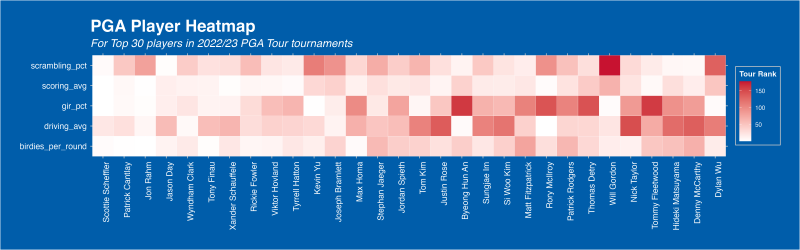
Player Performance Heatmap
First, it’d be good to take a look at player performance as a whole. A good way to visualise this is with a heatmap. You can see this below, and it includes the Top 50 players based on my overall rank metric.
To create the overall rank metric, I have ranked each player on the PGA Tour by the metrics listed above. I have then created a sum of ranks for each player, and ranked them again based on this, to create their overall rank.
I have then filtered for the Top 30 players, for readability, but this can be easily replicated for all players, or a specific group of players, using R dplyr’s handy filter() function.
Reading into our heatmap, we can see that the top players all perform extremely well across all categories. This is expected of course, as their ranking is generated from their performances here, but it is still interesting to see that consistent domination of PGA Tour statistics that the top players are able to achieve.
It’s also interesting to see that driving distance, a hot topic in the current age of big-hitting golfers, is not a prerequisite for elite performance levels. Morikawa, Kim, Conners, and Wu all perform outside the Top 50 in average driving distance, yet remain Top 20 overall.
Perhaps most interesting, Burmester is an elite performer in all statistics… except scoring. I’d predict a case of the ‘yips’ may be may play here. Happens to the best!

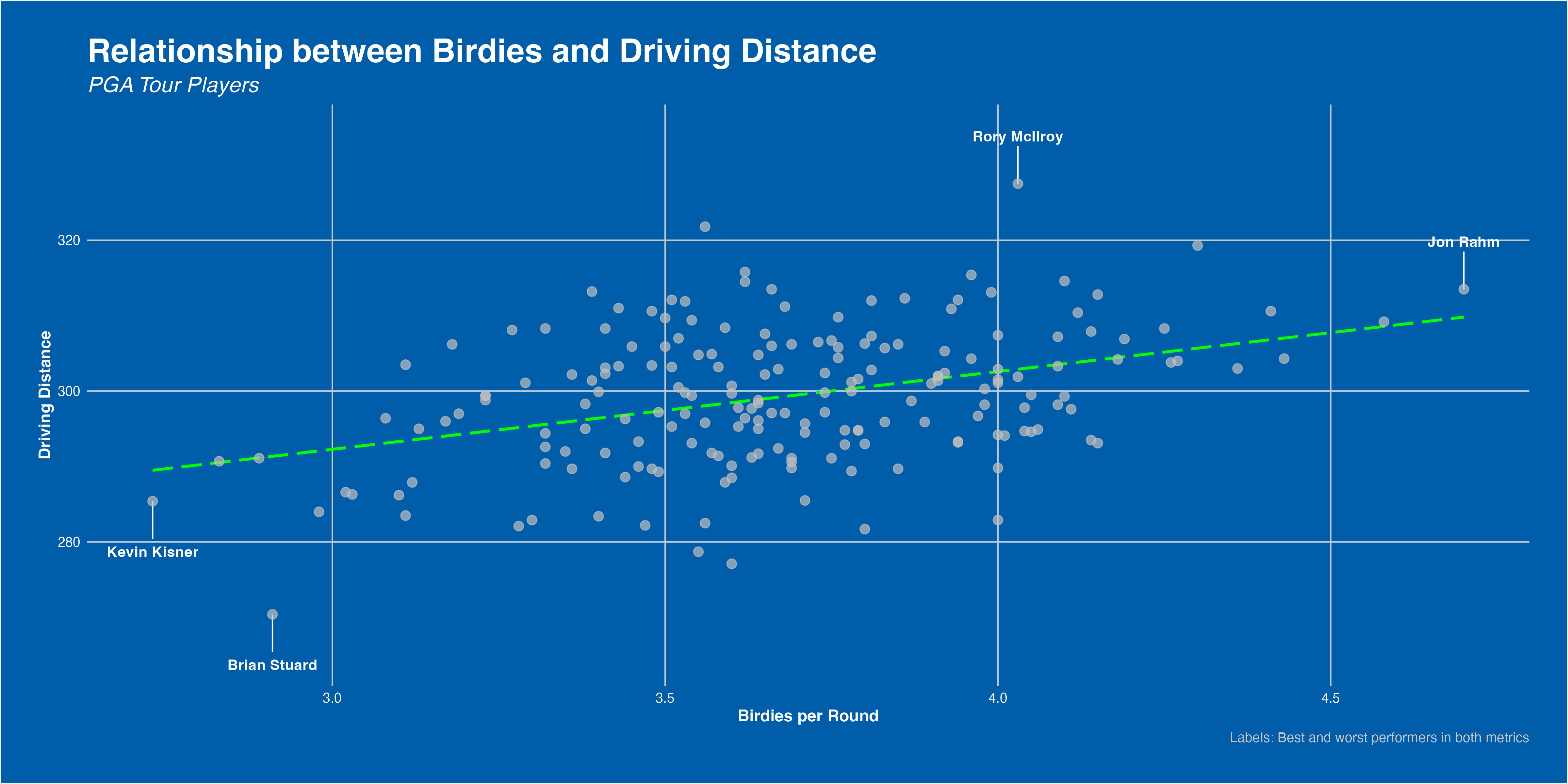
Big Hits, Small Scores?
As mentioned, hitting big off the tee is well in trend in the modern golf game. Better technology and technique, more demanding hole lengths, and the never-ending pursuit to maximise risk-reward are all drivers of this.
But, does crushing the ball as far as possinle actually yield more birdies? Well, somewhat. As our plot shows, there is a clear positive correlation between the two metrics. Longer driver’s tend to yield more birdies per round, though not unanimously. Rather, each player must find the risk-reward balance that suits them. Distance is a plus, but you must keep the ball in play consistently to make bank.
Linear Regression Model
We saw above that driving_avg had a positive correlation with birdies_per_round. That is, players’ who drive the ball further tend to score more birdies per round. However, that does not mean that players score more birdies because they drive the ball further - we have not shown causality between these two variables.
In this section, I try to determine if there is any causality between driving distance and shooting better scores. That is, does increasing average driving distance generate lower scores in PGA Tour events?
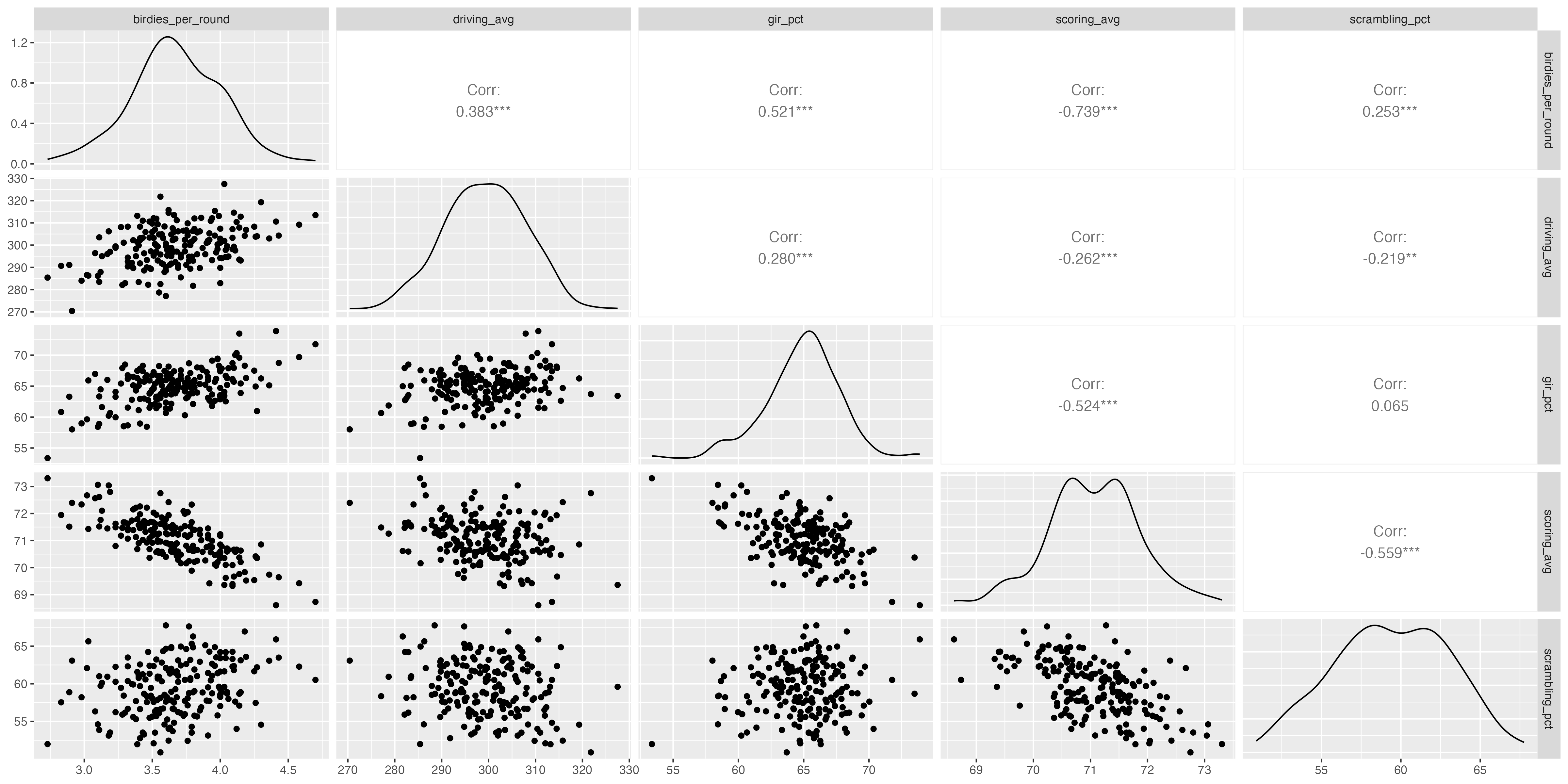
Variables at Play
Here, I show a correlation matrix of all the variables that I studied during my iterative regression process.
All of our metrics show negative correlations with scoring average. That is, improvements to a player’s driving_avg, gir_pct, and scrambling_pct all tend to show reductions in their scoring_avg. While driving_avg has the weakest correlation of our studied variables, that doesn’t really matter. Rather, what we are trying to see is whether or not increasing driving_avg yields a negative (improved) scoring_avg when we keep driving_avg, gir_pct, and scrambling_pctfixed. That will tell us with reasonable strength if driving_avg is a cause of better scores at the highest level of golf.
Model Definition
I have used a linear regression model to undertake this study - this offers simplicity and clarity to the average reader without sacrificing a great deal of model accuracy.
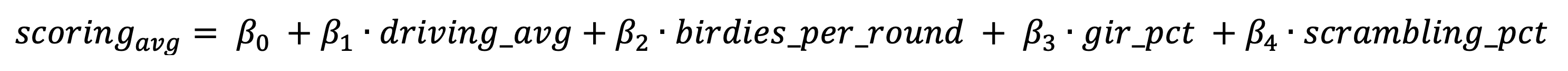
Model Results
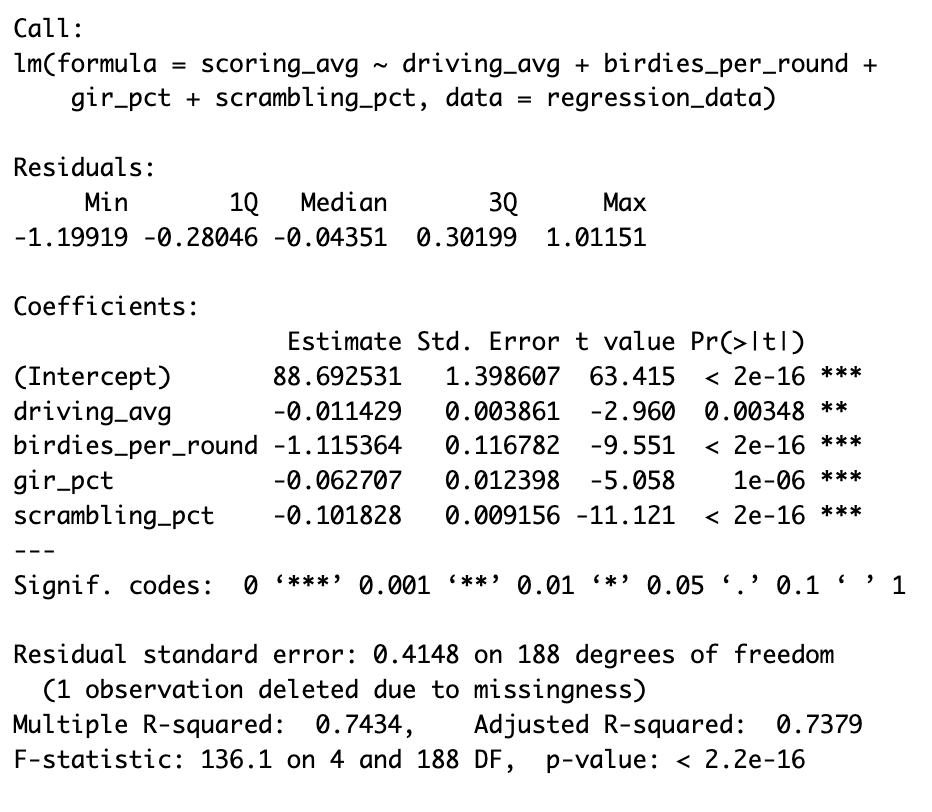
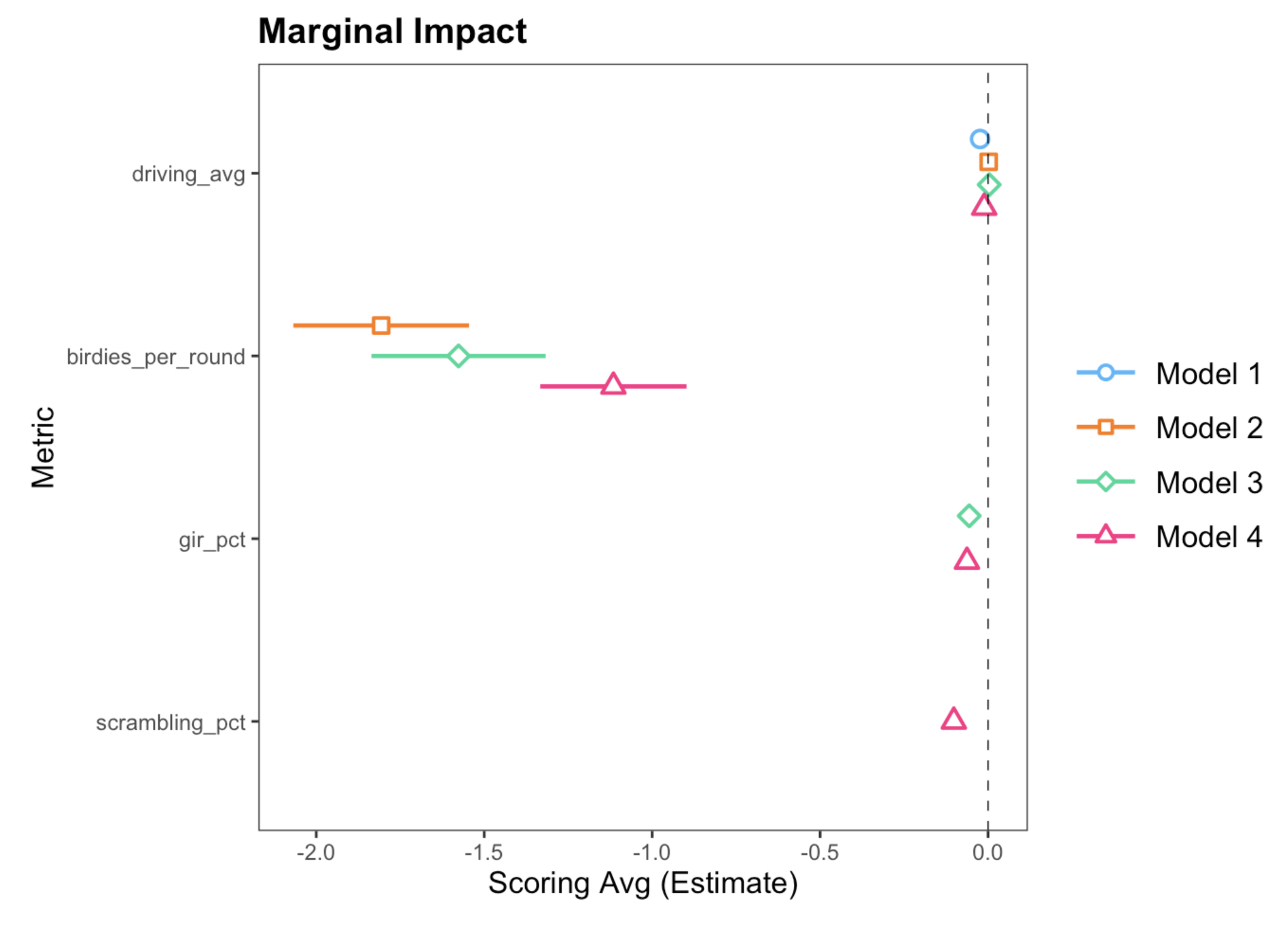
The output of our model confirms some obvious things, but also shows some more interesting points.
Birdie Rate
Firstly, birdies_per_round is the most influential variable by far. This is expected, since it is our only direct scoring metric - a birdie reduces a player’s score by 1 and therefore should impact scoring_avg by roughly 1. However, perhaps more interestingly, our final model shows that increasing the number of birdies per round by 1, generates a reduction in scoring average by 1.1. Why is that interesting? Well, how does a birdie generate more than its sum in scoring benefits?
This is counter-intuitive, in my opinion. I would have thought that the effect here would be < -1, since scoring a birdie does not guarantee the lack of a forthcoming bogey. This would suggest that a birdie is not quite worth -1, since there is a probability that score will slip later on. However, the result suggests the contrary - players who score one additional birdie may experience a mental boost that allows them to go on and score more birdies.
Greens in Regulation and Scrambling
Variables gir_pct and scrambling_pct both perform similary. That is, a 1 percentage point increase in either metric generates an estimtated 0.1 improvement in a player’s scoring_avg. This perhaps seems quite small, achieving GIR or being able to consistently scramble should be critical skills. This likely tells us that PGA level players acheive GIR and scramble relatively similarly, and the money-makers are the ones who are able to hole-out putts consistently.
Variable of Interest: Average Driving Distance
Our results here tell us that a 1 yard increase in average driving distance yields a 0.01 reduction in player’s scoring average. That means, for each yard a player can increase their average driving distance, they will score 0.01 better on average.
This may seem very small, but I find the results here very interesting. Primarily, driving distance does lead to a non-negative increase in tournament performance. Note that a 1-yard increase is relatively small, unless you have already reached diminishing returns to driving distance (i.e. Rory McIlroy is unlikely to increase driving distance, since he already hits it so far). Hence, a 10-15 yard increase can start to have tangible effects on a player’s tournament results. Take Viktor Hovland as an example; he’s increased his driving distance by approximately 10 yards since 2019, and now finds himself right at the sharp-end of PGA tournaments frequently.
Regression Diagnostics
From our output tables, we can see that all of our variables are significant at the 1% level, with the exception of driving_avg, which is significant at the 5% level. This defends the robustness of the model, although isn’t completely perfect. Our adjusted-R-squared value is 73%, a level that I am happy with. Again, it’s good but not perfect. Overall, the initial checks show that our model performs well, and I would not expect these metrics to be significantly better.
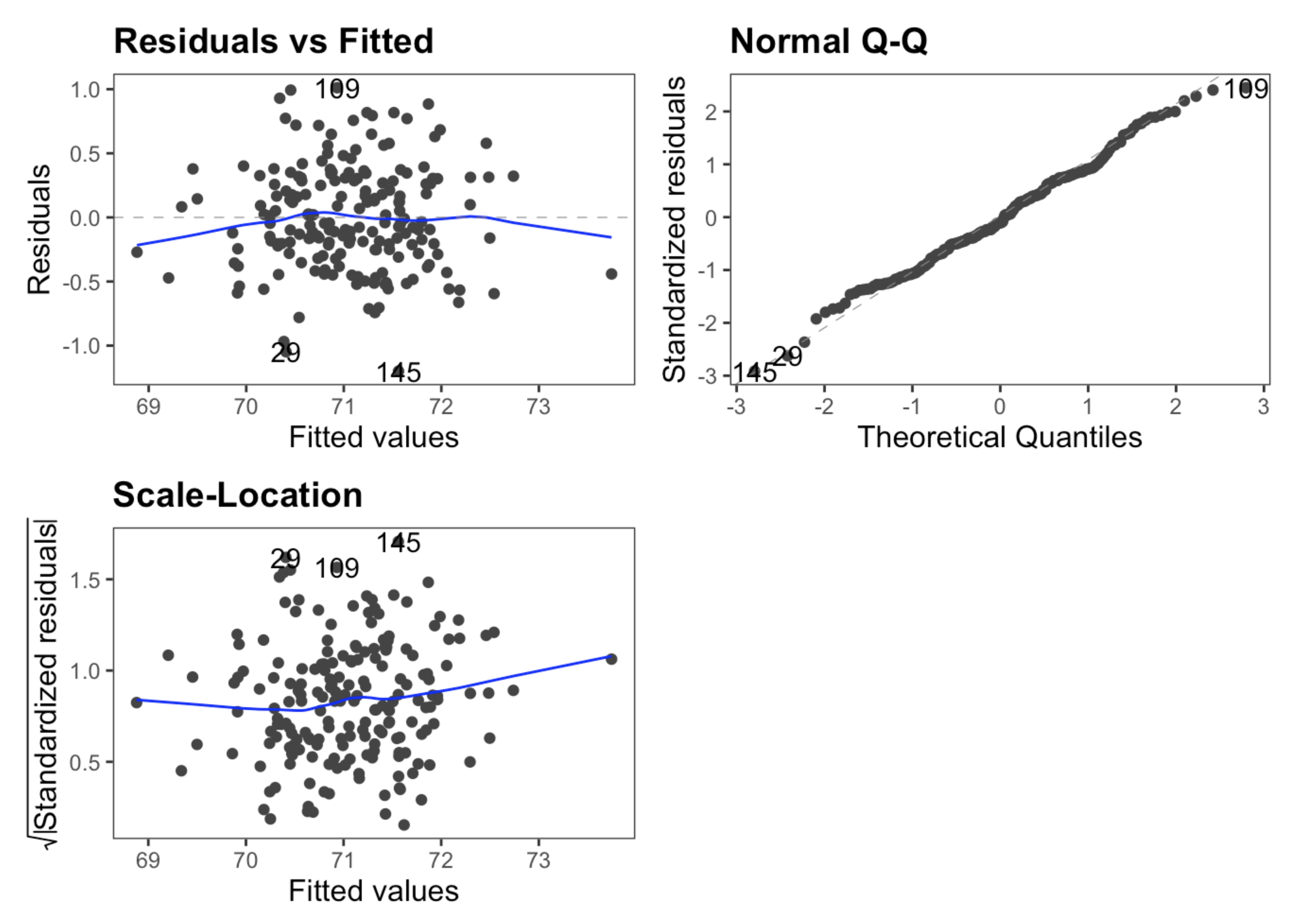
From a diagnostic plot perspective, our model also holds up. Our residual versus fitted plot shows relatively strong randomness, with some difficulties at the tails that I am not overly concerned with in this context. The same can be said for the Normal Q-Q plot, which certainly passes the ‘fat pen test’. For scale-location, we are looking for a horizontal trend, and I would argue that we meet acceptable levels here too.
Code
Here, you can find the code I used to perform each of the above analyses.
Packages
|
|
### Database Connection
|
|
Database Cleaning
|
|
|
|
Heatmap
|
|
### Driving Distance vs. Birdie Rate
|
|
Regression
|
|